Using/Model
Introduction
This document aims to provide a fairly detailed mental model for Darcs from the user perspective. There will be a very tiny bit of maths when we talk about repositories as sets of patches but it will just be a precise way of saying that you can think your repository either as a set or as a sequence of patches. This is mostly aimed at users who have some experience using Darcs. For non Darcs users, we hope this will give you an idea for what you might do with Darcs.
Working and patches
There are two levels of state you need to be aware of:
- the working directory
- the patches
The working directory is where all your work happens. The patches consists of your saved work. You may occasionally hear Darcs hackers talking about the “pristine” state, which you can treat as being equivalent to the patches.
You can view Darcs commands in terms of how information flows between the working directory and your patches. For example, running darcs record saves content from the working directory into your patches:
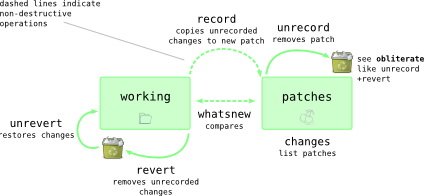
The same sort of perspective if useful for commands that go beyond the local repository
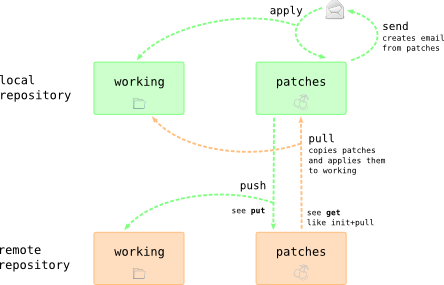
Tips:
- The pristine state is a representation of a file tree that corresponds to the set of patches You can think of it as an optimisation because Darcs should always be able to reconstruct the pristine state from your patches. Indeed, this is what the
darcs repaircommand tries to do. - The revert and unrevert command use a special internal patch that is not mentioned in this table
- The
sendandapplycommands use patch bundle files that people tend to exchange by email
Patches
High level patches
Darcs uses a high-level notion of patches. For example, darcs would represent a file move like this
move ./tests/ssh.sh ./tests/network/ssh.shFrom a user perspective, there are essentially two kinds of patches: primitive patches and named patches.
Named patches are patches which contain a list of primitive patches and some metadata information (such as the patch author). Named patches are what Darcs offers you when you run commands like darcs pull and darcs push.
Among primitive patches, the kind you’re most likely to see a lot of in Darcs are “hunk” patches. Hunk patches are changes to contiguous regions of text (note that this is a slight difference from Git). Other examples of primitive patch types you will encounter are add file, add directory, and token replace. Primitive patches are what Darcs offers you when you run commands like darcs whatsnew and darcs record.
Patch contents change with context
The textual representation of each patch depends on what other patches were applied before. For instance, suppose we had a named patch “Say hello”, which adds the line “hello” to the third line of a file A
$ darcs log --last=1 -v
Thu Sep 16 15:37:14 BST 2010 Eric Kow <kowey@darcs.net>
* Say hello.
hunk ./A 3
+helloIf we later apply this patch after some other patch that has renamed A to B, the textual representation would change
$ darcs log --last=2 -v
Thu Sep 16 15:37:14 BST 2010 Eric Kow <kowey@darcs.net>
* Say hello.
hunk ./B 3
+hello
Thu Sep 16 15:39:01 BST 2010 Eric Kow <kowey@darcs.net>
* Rename A to B.
move ./A ./BBut we still think of “Say hello.” as being the same patch in both cases. Note also the timestamps of the patches.
First, the “Say hello” patches in both cases have the same timestamp. This is because they are the same patch in Darcs’ eyes (just with a different textual representation according to context). Second, the “Say hello” patch has an earlier timestamp than the one renaming A to B, even though it is applied on top of it. This is because patches can be reordered.
Tips:
- Primitive patches are what the Darcs UI calls changes.
- It’s sometimes convenient to get low-level diff (1) style patches. Just use the
darcs diffcommand. - Concerned your patches changing textual representation? Think of it is a more principled approach to applying patches. Darcs uses a set of repeatable (unchanging) and reversible rules to determine these adjustments. If you go from one context and back, we guarantee that you’ll get the same patch representation back.
Set of patches
A darcs repository is defined as a set of patches; however, this set of patches manifests concretely as a sequence of patch representations. In other words, we have an abstract (set-of-patches) view on the one hand and a more concrete (sequence-of-patches) view on the other hand. Said a little bit more formally, there are two orders to consider:
- a partial order on patches dependencies
- a total order on patch representations [order patches were applied]
The total order (relation #2) is what darcs presents to you when you browse patches with a command like darcs changes. This second ordering respects the first: the order relation #2 is a superset of the relation #1 (in other words, Darcs will never let you add patches to a repository without first adding their dependencies).
Why the set-of-patches view is useful
Looking at the set of patches rather than the sequence of representation gives a more high-level view of what darcs does. It is especially useful when undoing patches or merging with other repositories. Suppose you have the following sequence of patch representations:
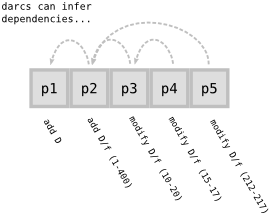
- p1: create directory D
- p2: add a file to D, D/foo with 400 lines of text
- p3: change lines 10-20 of D/foo
- p4: change lines 15-17 of D/foo
- p5: change lines 212-215 of D/foo
Darcs will allow you to conveniently undo patches without them being last in the history. In other words, in the scenario above, you can undo p4 without having to undo p5. To make this happen, Darcs rearranges the history by bubbling p4 up to the top and straightforwardly getting rid of it.
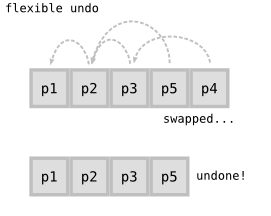
A more interesting case is what Darcs does not allow you to do. While it’s very happy for you to undo p4 while leaving p5 behind, it will refuse a patch like p3 unless you agree to undo p4 as well. The key difference is that p4 depends on p3 (we’ll explore the notion of dependencies later). Undoing the latter without the former is hard to make sense of, so it’s simply forbidden.
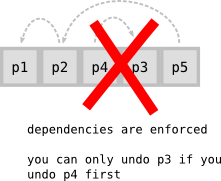
The set-of-patches way of understanding your darcs repository is useful because it avoids you thinking about the work Darcs is doing behind the scenes to detect and to preserve patch dependencies. Your primary focus can be whether or not Darcs allows you to add/remove patches to a set, and not so much why. If you’re interested in why, then the sequence-of-patches way of understanding things becomes useful.
Why the sequence-of-patches view is useful
The sequence-of-patches gives you a low-level understanding of how Darcs views your repository. As far as Darcs is concerned, all repositories are just sequences of patches.
On a more practical level, the sequence-of-patches viewpoint gives you an approximation of your repository history. It’s not an exact representation because Darcs allows patches to be reordered, but it’s good enough to get a rough sense of when things happened.
Tips for users:
- any permutation of a patch sequence allowed by Darcs leads to the same exact repository (if not, we have a bug)
- if you ever use matchers like –from-patch and –to-patch, it’s worth knowing that these matchers take the sequence-of-patches view of things. In other words “–from-patch X” means “patches from X to the last one in the sequence” and “–to-patch X” means “patches from the beginning of the sequence up to X”
Dependencies
Implicit dependencies
Patches can depend on each other. For all possible pairs of primitive patch types Darcs knows about, we have a definition for what makes one patch depend on another. As an example of such a definition: given a sequence of patches p1 and p2, if p1 creates a directory and p2 adds a file in that directory, then p2 depends on p1.
It wouldn’t be practical to describe all the possible pairs of dependencies and non-dependencies, but hopefully with a few examples, we can convey the sense that pairwise patch dependencies are what one might reasonably expect.
Suppose we have a darcs repository with just files, “a” and “o”, which we later rename to “apples” and “oranges” respectively. We later experience a change of heart and rename “apples” to “apricots”.
darcs log -v
3: Sun Sep 19 10:57:54 BST 2010 Joe User <user@machine.tld>
* Actually apricots make a better example (p3)
move ./apples ./apricots
2: Sun Sep 19 10:53:56 BST 2010 Joe User <user@machine.tld>
* Spell out filename for oranges (p2)
move ./o ./oranges
1: Sun Sep 19 10:53:50 BST 2010 Joe User <user@machine.tld>
* Spell out filename for apples (p1)
move ./a ./apples
0: Sun Sep 19 10:42:32 BST 2010 Joe User <user@machine.tld>
* a and o (p0)
addfile ./a
addfile ./oSo which patches depend on which? First, p1 and p2 both depend on p0 because it doesn’t make much sense to rename a file that does not even exist yet. Darcs would forbid you from undoing p0 without first undoing both p2 and p3 first and conversely, would not allow you to pull the latter without also pulling the former. On the other hand, p2 does NOT depend on p1 as the file names being moved do not have anything in common – we’d be comparing apples and oranges – nor does p3 depend on p2. But while p3 does not depend on p2, it does depend on p1. Does it depend on p0? Only indirectly. Darcs never gets to a point where it would ask itself if p3 depends on p0 because it can stop searching the minute it hits the brick wall of the p1 dependency.
Hunk patches
The most useful dependencies to know about are dependencies between hunk patches: as a rule of thumb, given two hunk patches p2 and p1, p2 depends on p1 if it overlaps or is adjacent to it.
In the diagram below, we show a series of hunk patches that build up a file with the lines “all the clean blue tables were duly occupied” (for compactness we use examples with one word per line).
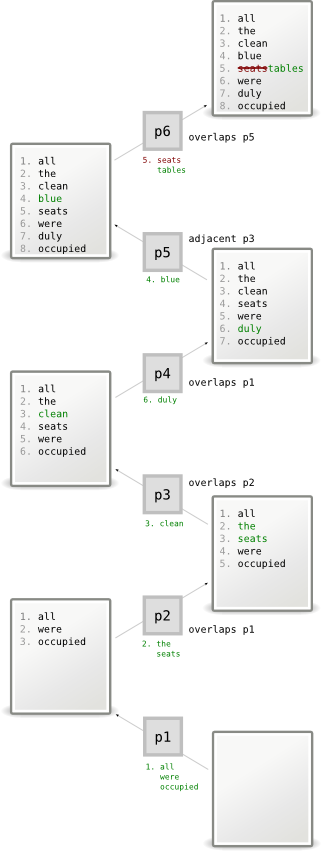
We can see some examples of what would cause patches to depend on each other or not. For example, the patch that inserts “clean” into the sentence overlaps with and thus depends on the patch which inserts “the seats”. Likewise, the patch that inserts “blue” is adjacent the one which inserts “clean”. However, the patch which inserts “duly” isn’t dependent on any of these as it’s neither adjacent nor overlapping.
Notes:
- We’ve been asked before why it’s important for adjacent hunks to depend on each other. It’s a bit tricky to explain, the basic idea being that allowing them to be independent would create line number ambiguities under cherry picking. For more details, see the developer documentation on commuting patches
Explicit dependencies
It is also possible to introduce explicit dependencies between named patches in Darcs. There are two ways of doing so. The first is darcs record --ask-deps which causes Darcs to offer you the ability to pick out patches that your recorded patch should depend on. The second way is with darcs tag. A tag is basically just an empty patch which depends on some other patches.
Merging without graphs
Earlier, we saw that repositories can either be viewed as a sequence or a set of patches.
Pulling patches from one repository into another involves patches being concatenated to the latter repository’s sequence (or unioned with its set, depending on your point of view).
Let’s walk through a couple examples of what this would look like in practice. In each of these examples, we’ll be pulling/pushing patches from a “Source” repository to a “Target” repository. We’ll be using a bit of informal notation, namely “cN” to indicate a patch that both repositories have in common, and “sN” and “tN” for patches which are only in the Source and Target repositories respectively.
Merging with cherry picking
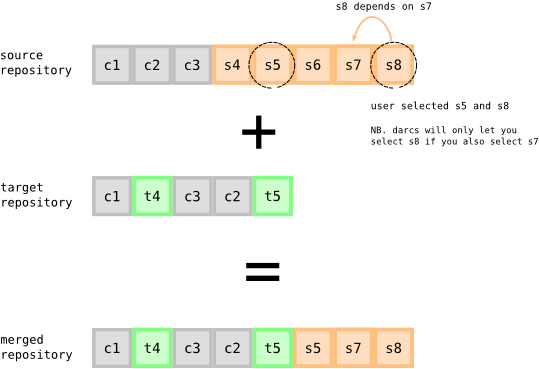
The diagram above shows the typical kind of merge you might perform in Darcs. When you run darcs pull, the interactive UI asks you if you want to select patches s4, then s5, etc. You mean to select s5 and s8, but Darcs refuses to let you pick s8 unless you also select the dependency s7, so you pick it too.
The result of this pull is that the patches you select (s5, s7, and s8) are adjusted to fit the new context (without s4, and with intervening t4 and t5) and appended. So from the sequence-of-patches point of view, the new repository has had three new patches appended to it, patches with the same identifier as from the source repository, but with slightly adjusted contents. From the simpler set-of-patches point of view, you just ignore that this business with patches being adjusted to context, simplying saying that now both your and the source repository have the patches c1-c3, s5, s7, and s8 in them.
Working directory
Sometimes when pulling and pushing patches to a repository, the repository may have unrecorded changes in the working directory. The working directory will also be merged to reflect the incoming patches. One way to think about this is to imagine the outstanding changes in the working directory as forming a sort of virtual floating patch that gets shifted over the incoming changes.
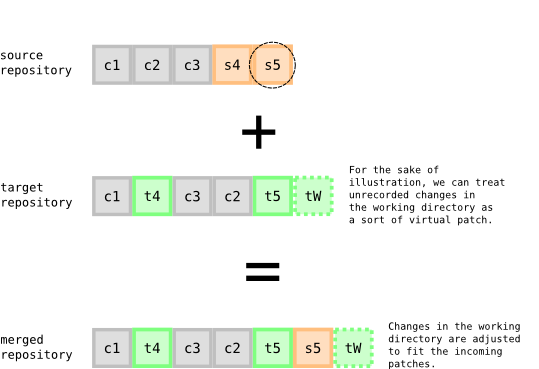
Notice that this virtual patch behaves a bit differently from the other patches in the target repository. Patches in the target repository stay put, only the unrecorded changes are shifted over and adapted to the incoming patches.
Summary
Darcs handles all of the cases aboving using the same basic mechanism. In other words:
- Merging consists in appending to a patch sequence
- The contents of darcs patches are automatically adjusted to fit their new context.
Tips:
- It is a good practice to record changes or revert the unwanted ones before merging. This behaviour encourages you to record more incremental patches (as opposed to massive ones) and also increases confidence when dealing with conflicts.
Conflicts
Conflicting patches cancel out
The distinction between your working directory and patches becomes particularly important when conflicts come into play.
Continuing our examples about merging repositories, suppose we pulled a patch s5 which conflicts with one of the target repository patches, t5.
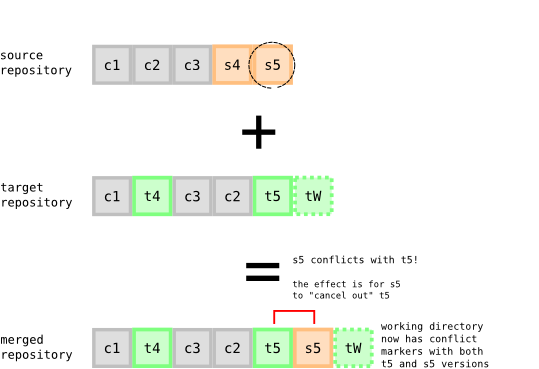
In abstract, the same basic story of merging is true: s5 is first adjusted to the new context that, among other things, includes t5 and then appended to the repository. But how is it adjusted? Darcs has a slightly unusual take on conflicts, namely that the effect a conflict is for the conflicting parts of a patch to cancel out. But that’s OK because no work is lost! The information about what both patches are trying to achieve is stored in the latter patch (the first patch is untouched). Moreover, Darcs uses this information about the two patches to mark up your working directory with conflict markers, telling you both sides of the story and asking you to reconcile them.
Delving a little deeper with a concrete example, suppose that patches c1 to c3 create a text file with the contents
All
the
seats
were
occupied
.(We wont worry about t4; it just modifies some other file). Suppose further more that the t5 replaced the line “seats” with “tables”, whereas s5 replaced it with “rooms”. The textual representation of s5 will be transformed into a conflictor:
$ darcs log --last=2 -v
Sun Mar 22 22:23:39 CET 2009 user@machine
* in fact it was rooms (s5)
conflictor [
hunk ./a.txt 3
-seats
+tables
]
|:
hunk ./a.txt 3
-seats
+rooms
Sun Mar 22 22:23:09 CET 2009 user@machine
* in fact it was tables (t5)
hunk ./a.txt 3
-seats
+tablesIt’s not particularly important to understand the details of what a conflictor is. What is more useful is to be aware that pulling a conflicting patch results in transforming the conflicting parts into some sort of conflict-tracking representation, and that this representation tries to take note of both the original patch (s/seats/rooms/) and other parties in the conflict (s/seats/tables/).
Furthermore, a key principle to keep in mind is that as far as the patches side of a repository is concerned, all sides of the conflict cancel out. That is, the effect of the s5 patch (in this conflict-tracking representation) is to nullify the t5 patch, so that effectively neither side of the conflict has happened. The text file, in the “patches” side of the repository, effectively reverts to the original “All the seats were occupied.”… which is where conflict marking comes into the picture.
Marking conflicts
Conflict marking in Darcs is something which happens only in your working directory. When Darcs detects a patch with a conflict-tracking representation, it can use the information to indicate you have a conflict. Darcs does this by adding conflict markers to your working directory. Revisiting the example from above:
All
the
+v v v v v v v
+seats
+=============
+rooms
+*************
+tables
+^ ^ ^ ^ ^ ^ ^
were
occupied
.Keep in mind that as far as the patches are concerned, both sides of the conflict have canceled out, so the information introduced in the conflict marking is considered to be new unrecorded changes.
$ darcs whatsnew
hunk ./a.txt 3
+v v v v v v v
hunk ./a.txt 5
+=============
+rooms
+*************
+tables
+^ ^ ^ ^ ^ ^ ^In the example, the line “seats” (from cancelling out both sides of the conflict) is surrounded with information from conflict marking.
Conflict marking is a repeatable operation and affects your working directory only. If you find yourself making a mistake during conflict resolution and wanting to recover the original conflict marking, you can run darcs revert followed by darcs mark-conflicts.
Resolving conflicts
So Darcs reacts to conflicts by canceling out the conflicting bits of a patch and then providing mark-up on top of this. What happens when the conflict has been resolved, and for that matter how can we tell that it has been resolved?
The short story is that a conflict is resolved if a patch depends on all parties in the conflict. In other words, if there is a patch created on top of the conflictor itself. If this sounds reasonable in principle, it could be worthwhile to think about some things which should NOT be treated as conflict resolutions:
- Patches which only affect non-conflicting parts of conflicting patches should not be treated as conflict resolutions. Subsequent patches that only modify the bottom parts of the file should not be treated as conflict resolutions.
- Patches which merely depend on one of the parties should not be treated as conflict resolutions. Suppose for example I have a series of patches that modify a file. If the first of these conflicts with a patch that outright removes the file, it would be silly to say that the subsequent patches resolve that conflict. They merely extend it.
Summary
Key principles:
- There can be more than two sides to a conflict
- Pulling a conflicting patch results in that patch having a conflict-tracking representation
- All sides of a conflict cancel out (in your patches)
- Conflict marking happens in your working directory only, and as a standalone step
TODO’s
- What happens in multi-party (> 2) conflicts
- Do we need to point users to examples of patches that only partially conflict?
- Do we need to talk about what happens when you have conflicting changes in the working directory as well?
- Internal conflicts: pushing patches with conflicts
Acknowledgements
This tutorial uses some icons from the Tango set, which are licensed under a Creative Commons Attribution Share-Alike license.